
R Intro
18 Apr 2019 | R IntroR 강의 노트
0. 준비
- 개인노트북(아래 설치과정 참조 바랍니다. 매우 쉽습니다)
- 없으면 몸만 오시면 됩니다.
1. Install R, RStudio
1.1 R
해당 링크는 국내의 R 저장소 중 한 곳이다. 위 화면에서 Download R 3.5.3 for Windows를 누르면 R이 다운로드 된다. 설치과정에서 나오는 옵션들의 선택은 모두 다 기본으로 한다.
1.2 RStudio
RStudio는 R을 위한 가장 인기있는 IDE(통합개발환경)이다. 해당 링크에서 Windows용을 다운로드한 후 모두 기본 옵션으로 설치하도록 하자.
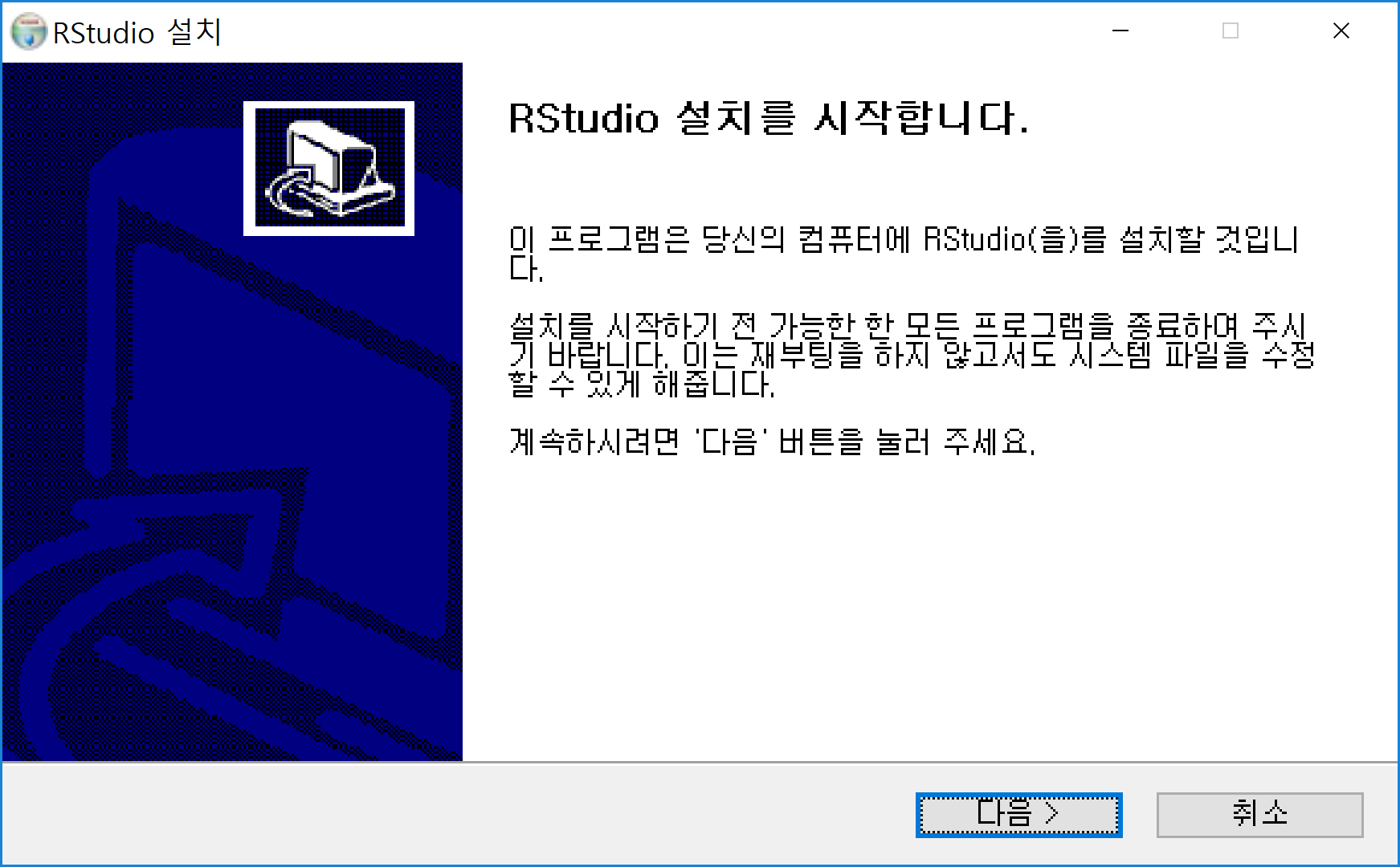
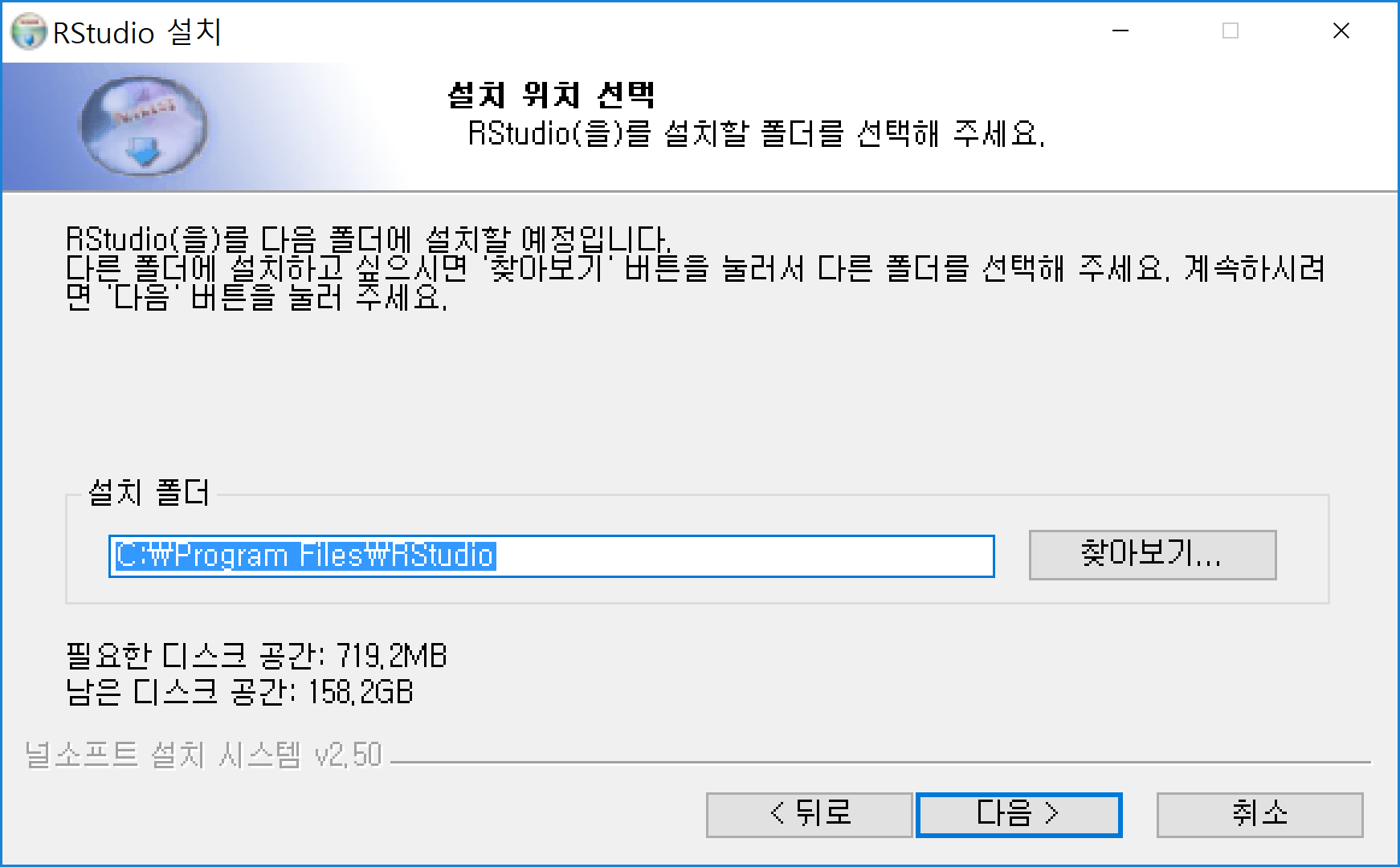
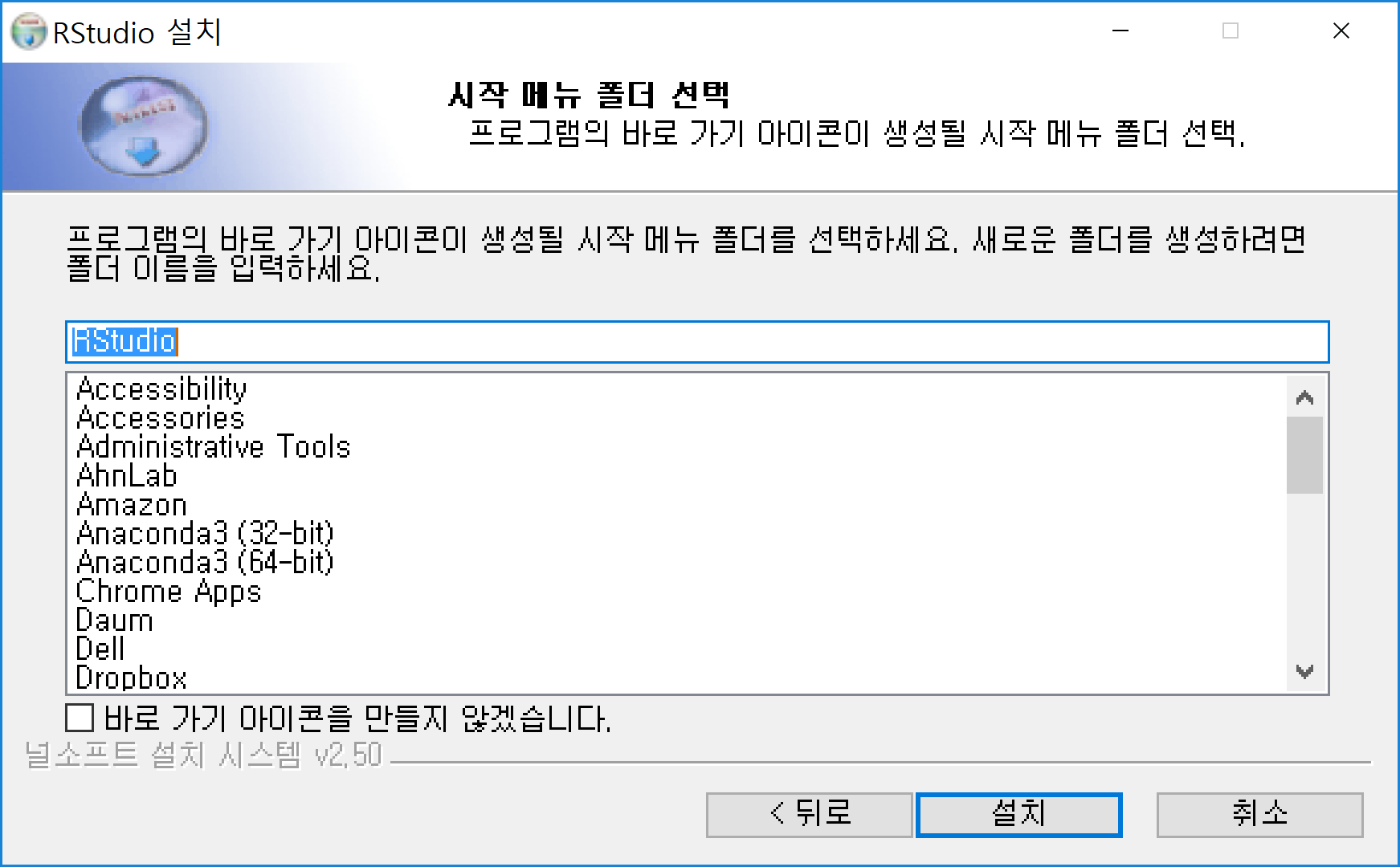
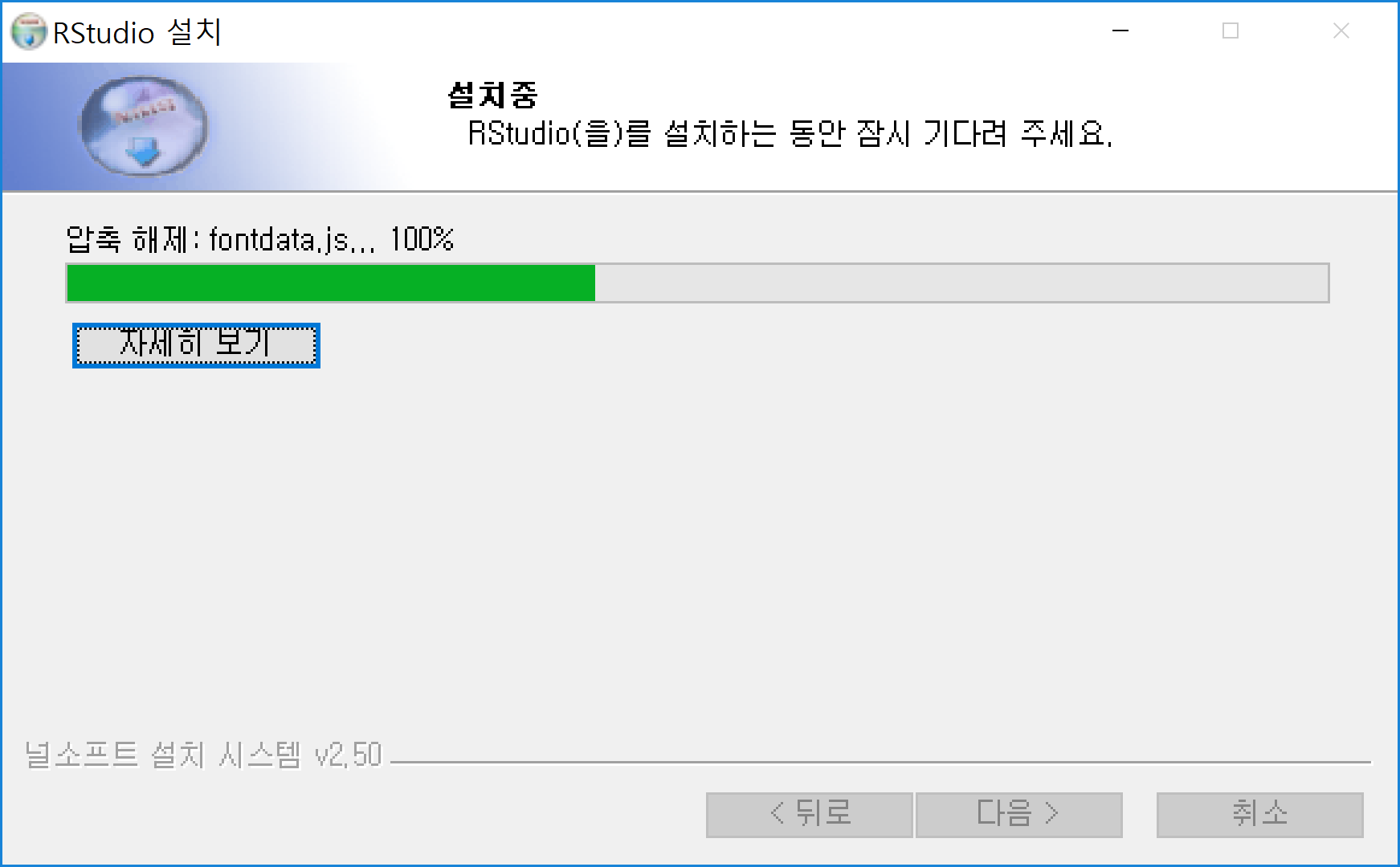
설치된 RStudio 아이콘을 클릭하면 실행이 되고 다음과 같은 화면이 나타난다.
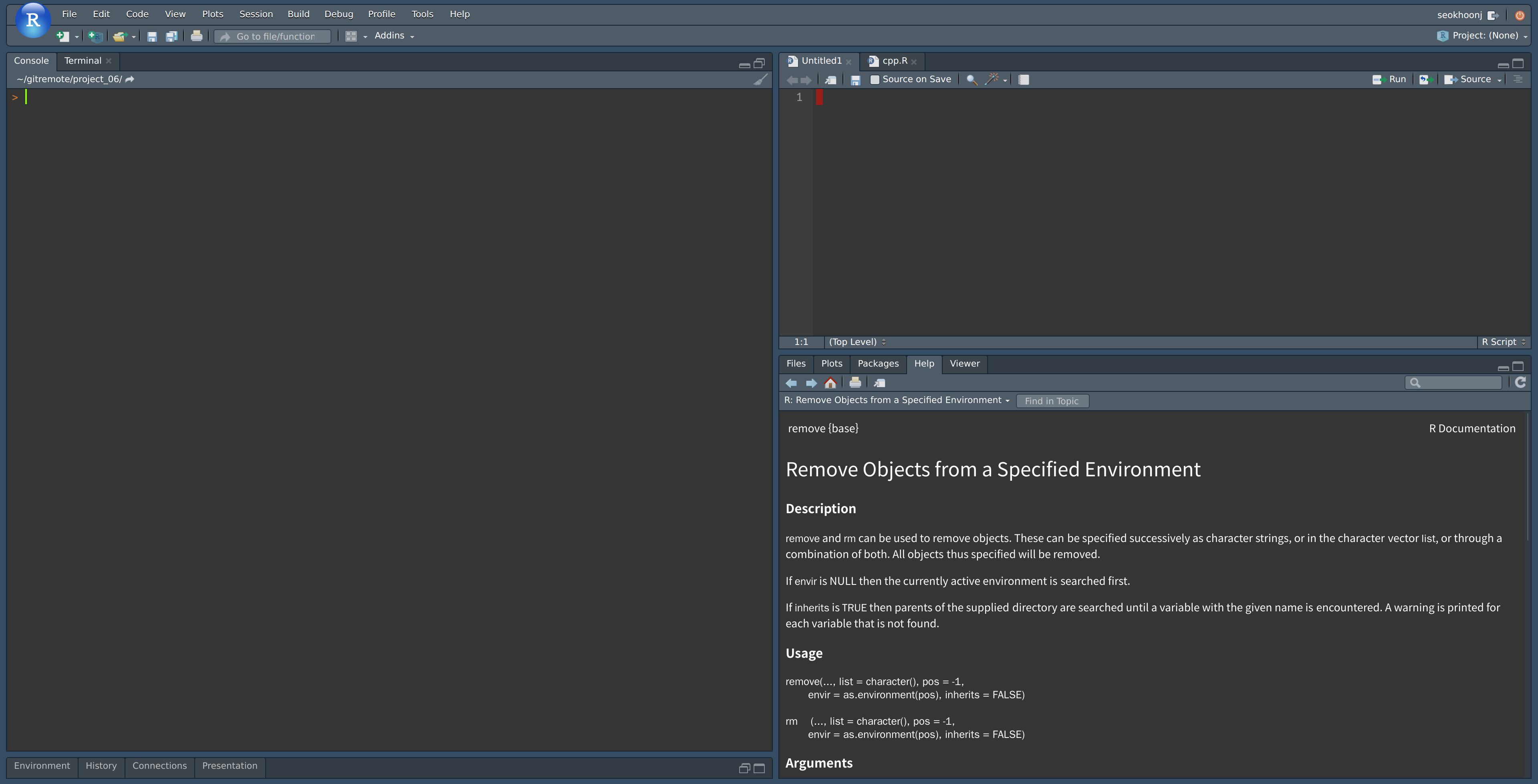
왼쪽의 콘솔창에 다음의 코드를 복사한 후 엔터를 누르자.
install.packages("tidyverse")
install.packages("Matrix")
install.packages("reshape2")
install.packages("sqldf")
install.packages("data.table")
install.packages("Hmisc")
install.packages("openxlsx")
install.packages("rJava")
install.packages("xlsx")
install.packages("stringi")
install.packages("microbenchmark")
install.packages("doParallel")
install.packages("party")
install.packages("rpart")
install.packages("randomForest")
install.packages("xgboost")
library(devtools)
install.packages("seokhoonj/ecos")
해당 패키지들이 설치되는 것들을 볼 수 있을 것이다. 이것으로 R을 사용하기 위한 모든 준비가 끝났다.
<---4월 25일 세션은 여기까지 준비해 주시면 됩니다. 세션을 마친 후 각자 자리에서 설치하여 사용하시면 되므로 준비가 없더라도 크게 문제는 없습니다.
다만, 직접 코드를 치면서 해보시는 게 실력을 키우는 더 좋은 방법이긴 합니다:)
2. R’s history
통계 분석 전용 언어인 R은 뉴질랜드 오클랜드 대학교 통계학과 교수인 Ross Ihaka, Robert Gentleman의 주도하에 만들어 졌다.
비슷한 통계 언어(?)로 SAS/SPSS/STATA 등이 있지만, 이들과 달리 R은 무료이며 훨씬 더 유연하다. 대부분의 통계기법들은 R에서 이미 패키지화 되어 있으며, vignette으로 쉽게 사용할 수 있게 문서화가 잘 되 어 있다.
3. Package 설치하기
R은 다양한 패키지를 제공한다. 실시간으로 업데이트 되는 최신의 통계기법을 전부 설치하는 것은 비효율적이므로 본인이 필요한 패키지를 설치하여 사용하도록 한다.
install.packages("dplyr") # by Hadley Wicham
library(dplyr)
install.packages("tidyverse") # by Hadley Wicham
library(tidyverse)
install.packages("devtools") # by Hadley Wicham
library(devtools)
install_github("seokhoonj/ecos") # by me
data("tableList")
4. 데이터 타입
4.1 자료형
NULL: no data
Logical: boolean (TRUE, FALSE)
Int: 정수
Double: 부동소수점
Complex: 복소수
Character: 문자열
List: 리스트
Closure: 함수
R 에서 클래스는 변수가 가지는 속성의 하나이다. 따라서 자료형과 클래스는 같은 값을 가지지 않을 수도 있다.
x <- TRUE ; cat(class(x), typeof(x), object.size(x), "\n")
x <- 1L ; cat(class(x), typeof(x), object.size(x), "\n")
x <- 3.14 ; cat(class(x), typeof(x), object.size(x), "\n")
x <- "abc" ; cat(class(x), typeof(x), object.size(x), "\n")
x <- ls ; cat(class(x), typeof(x), object.size(x), "\n")
x <- matrix(cars) ; cat(class(x), typeof(x), object.size(x), "\n")
x <- cars ; cat(class(x), typeof(x), object.size(x), "\n")
x <- 1 # x라는 변수에 1을 할당
y <- 2 # y라는 변수에 2를 할당
z <- x + y # x + y를 계산하여 z라는 변수에 할당
z # z를 출력
4.2 vector
R의 계산이 파워풀한 이유는 바로 vector화 연산 때문이다.
x <- 1:10 # x에 1~10의 정수를 대입
y <- 2
z <- 5:15
x * y
x * z
4.3 list
# <- 와 = 은 변수에 값을 할당할때 같은 기능을 한다.
num = seq(5, 50, 5) # 5, 10, ... , 45, 50
string = "lingo"
df = iris
lst_x = list(num, string, df)
lst_x[[1]]
lst_x[[2]]
head(lst_x[[3]])
4.4 data.frame
R에서 데이터분석을 위해 가장 많이 사용되는 것은 데이터 프레임 구조이다. 여기서는 내장 dataset인 iris를 중심으로 분석해 본다.
4.4.1 data load
# 현재 디렉토리 확인, 입출력 데이터 셋의 경로가 된다.
getwd()
# 설명의 편의를 위해 일단 openxlsx package를 불러오고
library(openxlsx)
# 내장 dataset인 iris를 엑셀로 쓴다.
write.xlsx(iris, file = "iris.xlsx")
# 해당 위치에 있는 엑셀 데이터를 불러오려면 다음과 같이 파일명을 적는다.
df = readWorkbook("iris.xlsx", sheet = 1, startRow = 1)
head(df)
# 만약 file을 직접 선택하고 싶으면 다음과 같은 코드를 사용해도 된다.
library(openxlsx)
df = readWorkbook(file.choose(), sheet = 1, startRow = 1)
head(df)
4.4.2 data slicing
df = iris
df[1, 1] # 행과 열을 선택한다.
df[1:3, 1:3] # 행과 열을 연속적으로 선택한다.
df[, "Species"] # 열을 이름으로 선택한다.
df$Species # 열을 이름으로 선택하는 다른 방법
df[, c("Sepal.Length", "Species")] # 복수의 열을 이름으로 선택한다.
df = cars
subset(cars, speed == 10)
subset(cars, speed == 10 & dist = 34) # AND condition
subset(cars, speed == 10 | dist = 34) # OR condition
4.4.3 reshaping 과 sql 연계
library(reshape2)
df = mtcars
head(df)
summary(mtcars)
plot(mtcars)
cor(mtcars)
4.4.4 simple linear regression
model = lm(dist ~ speed, data = cars)
summary(model)
plot(model)
plot(dist ~ speed, data = cars, col = "blue")
abline(model, col =
# cor()로 구한 Pearson 상관계수를 제곱하면 R^2와 동일
cor(cars$speed, cars$dist)^2
# regmodelsion diagnosis
par(mfrow = c(2, 2))
plot(model)
par(mfrow = c(1, 1))
qqnorm(resid(model))
qqline(resid(model))
shapiro.test(resid(model))
4.4.5 Multiple Regression
pairs(attitude) # plot(attitude) 와 같음
model1 = lm(rating ~ ., data = attitude)
anova(model1)
model2 = lm(rating ~ complaints + learning + advance, data = attitude)
anova(model1, model2) # 두 모델을 비교하는 F-test
model3 = lm(rating ~ complaints + learning, data = attitude)
anova(model1, model2, model3)
summary(model3)
실제로 forward selection, backward elimination, stepwise selection 등도 이미 만들어져 있음
엑셀은 가독성이 떨어진다.
Comments