영어 원본 보기: Detecting regime shifts across underwriting cohorts
1. 동기
장기 건강보험 코호트 포트폴리오를 분석할 때 실무자가 자주 던지는 질문은 두 가지이다.
- 최근 인수 코호트가 이전 코호트와 다른 양상을 보이는가?
- 그렇다면 변화는 언제 일어났는가?
장기 보험에서 코호트 패턴이 깨지는 트리거는 보통 다음 4가지다.
- 급격한 보험료 조정 — 인상 또는 인하
- 상품 보장 내용 변경 — 보장 항목·기간·면책 등의 구조 조정
- 가입금액 한도 변경 — 1인당 최대 가입금액 상·하한 조정
- Underwriting 가이드라인 변경 — 인수 자격·고지 항목·할증 기준의 개정
번들로 제공되는 experience 데이터셋의 SUR 종목에는 위
트리거 중 하나가 2024-04 시점에 발생했다고 가정한 합성 break 가 심어져
있다. 따라서 아래 시연에서 detect_cohort_regime() 이 잡아낼
명확한 변화점이 존재한다.
plot(tri_sur) 의 시각적 점검만으로도 최근 코호트의 초기
손해율이 과거보다 낮아 보일 수 있지만, 코호트별로 관측 창의 길이가 다른
상황에서 궤적 다발을 눈대중으로 살피는 것은 구조적 변화의 위치를
짚어내는 신뢰할 만한 방법이 못 된다.
detect_cohort_regime() 은 이 두 질문에 한 번의 호출로
답한다 — 인수 코호트를 regime (유사한 손해 추이를
공유하는 인수 코호트들의 묶음) 으로 그룹화하고, 그룹 사이의 break 시점을
함께 보고한다. 각 인수 코호트를 특징 벡터 (경과 기간
1, ..., K 에 걸친 궤적) 로 다루고, 인수 시점 순으로
코호트를 정렬한 뒤, 그 다변량 시퀀스에 변화점 또는 클러스터링 방법을
적용한다.
2. 데이터와 설정
library(lossratio)
data(experience)
exp <- as_experience(experience)
tri_sur <- build_triangle(exp[cv_nm == "SUR"], cv_nm)3. regime 탐지
기본 방법은 "ecp" 로, 데이터로부터 regime 의 개수까지
결정하는 비모수 다변량 변화점 알고리즘이다.
r <- detect_cohort_regime(tri_sur, K = 12, method = "ecp")
r
#> <CohortRegime>
#> method : ecp
#> value_var : clr
#> window (K) : elap_m 1, ..., 12
#> cohorts : 19 analysed (11 dropped)
#> regimes : 2
#> breakpoints : 24.03
#> PC1 / PC2 : 63.6% / 15.1%창 K 는 코호트 특징 벡터를 정의하는 경과 기간 수를
조절한다. 최소 K 기간 이상 관측된 코호트만 분석되며, 창이
짧은 코호트는 제외된다. K 를 늘리면 궤적을 더 많이 담을 수
있지만 최근 코호트가 그만큼 더 빠진다.
4. 요약과 regime 별 멤버십
summary(r)
#> Cohort regime detection summary
#> method : ecp
#> value_var : clr
#> window : elap_m 1, ..., 12
#> cohorts : 19 analysed (11 dropped)
#>
#> Regimes (2):
#> 1: 23.04, ..., 24.02 (11 cohorts)
#> 2: 24.03, ..., 24.10 (8 cohorts)
#>
#> Breakpoints: 24.03
r$labels
#> cohort regime regime_id
#> <Date> <fctr> <int>
#> 1: 2023-04-01 23.04, ..., 24.02 1
#> 2: 2023-05-01 23.04, ..., 24.02 1
#> 3: 2023-06-01 23.04, ..., 24.02 1
#> 4: 2023-07-01 23.04, ..., 24.02 1
#> 5: 2023-08-01 23.04, ..., 24.02 1
#> 6: 2023-09-01 23.04, ..., 24.02 1
#> 7: 2023-10-01 23.04, ..., 24.02 1
#> 8: 2023-11-01 23.04, ..., 24.02 1
#> 9: 2023-12-01 23.04, ..., 24.02 1
#> 10: 2024-01-01 23.04, ..., 24.02 1
#> 11: 2024-02-01 23.04, ..., 24.02 1
#> 12: 2024-03-01 24.03, ..., 24.10 2
#> 13: 2024-04-01 24.03, ..., 24.10 2
#> 14: 2024-05-01 24.03, ..., 24.10 2
#> 15: 2024-06-01 24.03, ..., 24.10 2
#> 16: 2024-07-01 24.03, ..., 24.10 2
#> 17: 2024-08-01 24.03, ..., 24.10 2
#> 18: 2024-09-01 24.03, ..., 24.10 2
#> 19: 2024-10-01 24.03, ..., 24.10 25. 시각화
plot(r) 은 코호트 궤적의 PCA(주성분분석) 산점도를 탐지된
regime 으로 색칠해 보여 준다. PCA 공간에서 regime 들이 잘 분리된다면
구조적 변화가 시각적으로 확인된 것이다.
plot(r)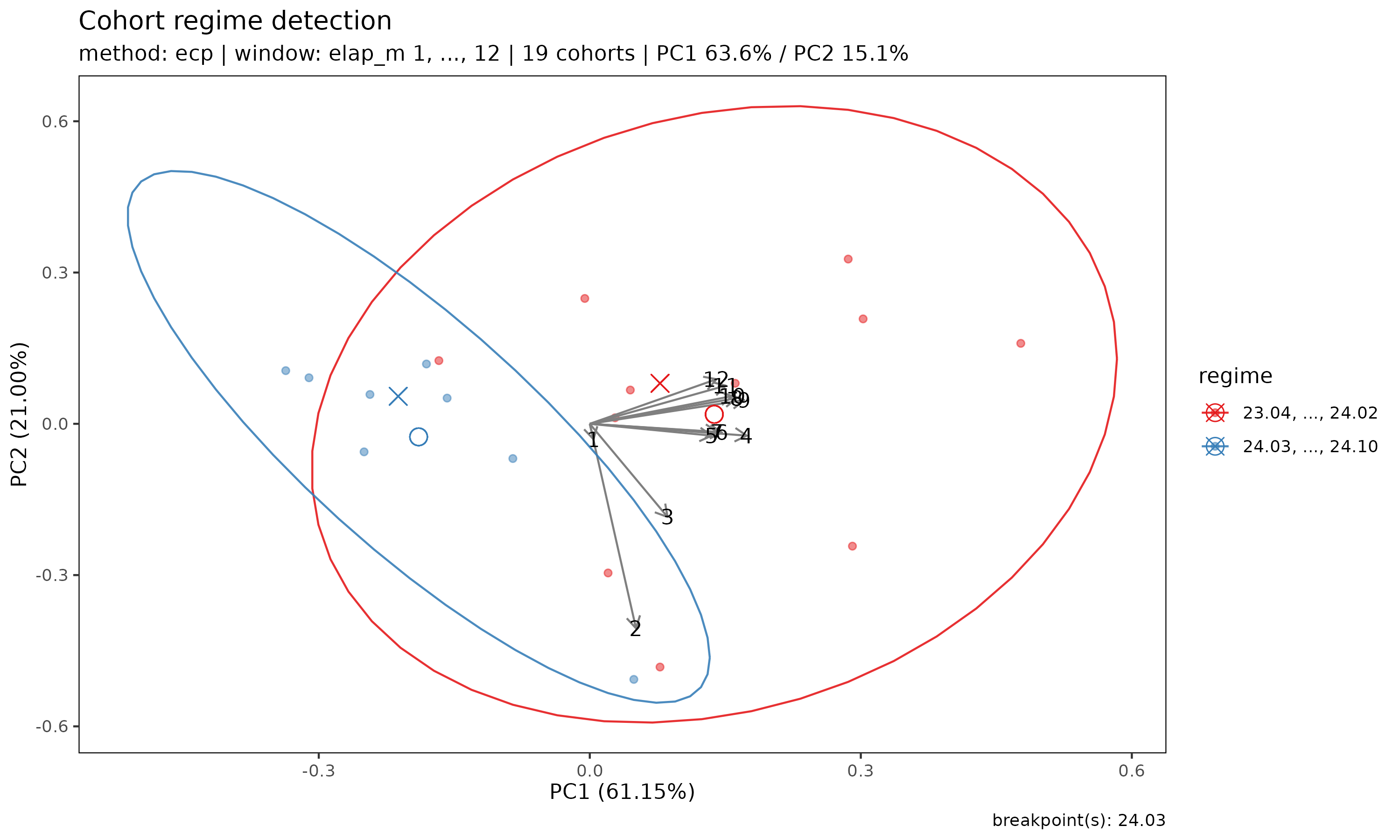
화살표는 각 경과 기간 특징이 PC 축에 기여하는 적재량을 나타낸다 — regime 들이 어떻게 다른지 (예: 변화가 주로 초기 경과에 영향을 주는지, 후기 경과에 영향을 주는지) 읽어내는 데 유용하다.
6. 방법 선택
"ecp"— 권장 기본값. 다변량, 비모수 알고리즘으로, 주어진 유의수준에서 regime 의 개수를 자동으로 탐지한다. 다른 방법보다 다소 느리지만 사전에n_regimes를 정할 필요가 없다."pelt"— 첫 주성분에 적용되는 빠른 일변량 변화점 탐지. 여러 변화점을 반환할 수 있으며, 궤적 변동이 한 축에 의해 주도될 때 유용하다 (print()출력의PC1 %를 확인 — 70% 초과면 PELT 가 신뢰할 만하고, 그보다 훨씬 낮으면"ecp"가 낫다)."hclust"— 표준화된 특징 행렬에 Ward 계층 클러스터링을 적용하고n_regimes개 (default:2) 클러스터로 자른다. 시계열 순서를 무시하므로 사후 검증용으로 적합하다. 시계열 기반 방법이 시점t에서 변화점을 잡았을 때hclust가 동일한 두 그룹 (모든 사전-t가 한 클러스터, 모든 사후-t가 다른 클러스터) 을 만들어 낸다면, 이 변화는 방법론적 인공물이 아닌 구조적 변화이다.
실무에서는 세 방법이 모두 일치하는 경우 — 위 SUR 예시처럼
"ecp", "pelt", "hclust" 가 모두
24.04 를 regime 경계로 지목하는 경우 — 실제 인수/요율
변경의 강력한 증거가 된다.
7. regime 개수 강제하기
regime 개수를 고정해 비교하고 싶을 때 — 예를 들어 2-regime 가설과
3-regime 가설을 비교할 때 — n_regimes 를 넘긴다.
r2 <- detect_cohort_regime(tri_sur, K = 12, method = "ecp", n_regimes = 3)
summary(r2)
#> Cohort regime detection summary
#> method : ecp
#> value_var : clr
#> window : elap_m 1, ..., 12
#> cohorts : 19 analysed (11 dropped)
#>
#> Regimes (3):
#> 1: 23.04, ..., 23.06 (3 cohorts)
#> 2: 23.07, ..., 24.02 (8 cohorts)
#> 3: 24.03, ..., 24.10 (8 cohorts)
#>
#> Breakpoints: 23.07, 24.03"ecp" 와 "pelt" 의 경우
n_regimes 는 요청값이다 (데이터가 허용하면 알고리즘이 그
수까지 regime 을 반환한다). "hclust" 의 경우에는 강제
컷이다.
8. fit_lr() 과의 관계
detect_cohort_regime() 은 fit_lr()
프레임워크의 수정이 아니라 전처리 진단 이다. 그 출력은 두
가지로 활용된다.
층화 적합: 명확히 구분되는 두 regime 이 탐지된 경우, 각 regime 부분집합에 대해
fit_lr()을 따로 적합하면 풀링 적합보다 더 또렷한 stable-CLR 추정값을 얻는 경우가 많다.요율 변경 문서화: 탐지된 변화점은 동반 논문의 Limitations 절에서 설명한 전처리 권고 (보험료 on-leveling 또는 익스포저 분해 ) 의 데이터 기반 기준점이 된다.